Hash Tables in JavaScript
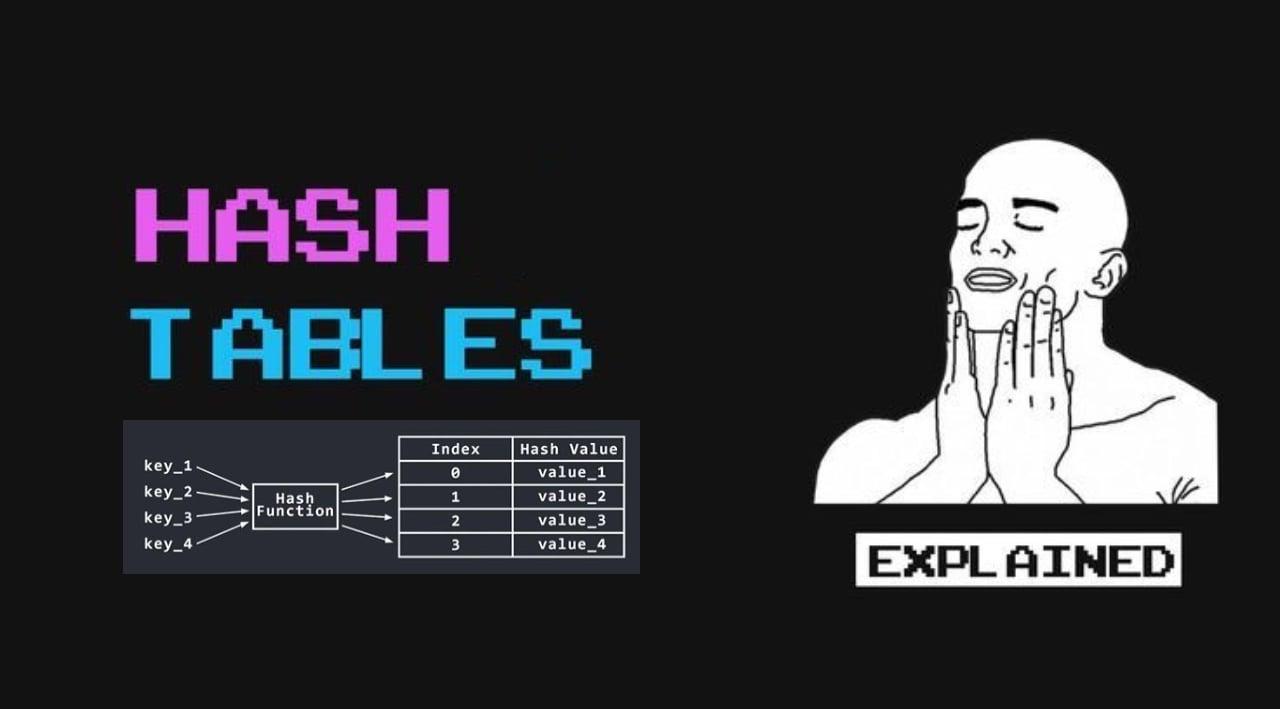
Hash tables are a fundamental data structure in computer science, providing efficient key-value pair storage. In this blog post, we'll explore what hash tables are, their benefits, and how to implement them in JavaScript. We'll also highlight the differences between a simple object and a hash table.
What is a Hash Table?
A hash table (or hash map) is a data structure that maps keys to values for highly efficient lookup. It uses a hash function to compute an index into an array of buckets or slots, from which the desired value can be found. The hash function transforms the key into a hash code, which determines where the key-value pair should be stored in the array.
Characteristics of a Hash Table
- Hash Function: A function that converts a key into an index in the array.
- Buckets or Slots: The array where the key-value pairs are stored.
- Collision Handling: Techniques like chaining (using linked lists) or open addressing (finding another slot) to handle situations where multiple keys hash to the same index.
Benefits of Hash Tables
- Fast Access: Hash tables provide O(1) average time complexity for search, insert, and delete operations.
- Efficient Memory Usage: They dynamically resize to accommodate more elements.
- Direct Access: Keys are directly mapped to their values using a hash function.
Difference Between a Simple Object and a Hash Table
- Simple Object: A plain JavaScript object uses the property names directly and does not involve hashing. It internally uses a more optimized structure, but it's abstracted away from the developer.
- Hash Table: Explicitly uses a hash function to determine the storage index for each key. It involves manually managing collisions and potentially resizing the underlying array.
Key Differences
- Access Method:
- Object: Direct access by property name.
- Hash Table: Access via hash function to determine the index.
- Underlying Mechanism:
- Object: Optimized internally by JavaScript engine.
- Hash Table: Explicit hash function and collision handling.
- Flexibility and Control:
- Object: Simple and easy to use.
- Hash Table: More control over storage and retrieval mechanisms, suitable for custom implementations.
Example of a Simple Object vs. Hash Table
Simple Object
const obj = {
name: 'Alice',
age: 30,
country: 'Wonderland'
};
console.log(obj.name); // Accessing value directly by property name
Hash Table Implementation
class HashTable {
constructor(size = 50) {
this.table = new Array(size);
this.size = size;
}
_hash(key) {
let hash = 0;
for (let i = 0; i < key.length; i++) {
hash = (hash << 5) - hash + key.charCodeAt(i);
hash |= 0; // Convert to 32bit integer
}
return hash % this.size;
}
set(key, value) {
const index = this._hash(key);
if (!this.table[index]) {
this.table[index] = [];
}
this.table[index].push([key, value]);
}
get(key) {
const index = this._hash(key);
if (!this.table[index]) return undefined;
for (let pair of this.table[index]) {
if (pair[0] === key) {
return pair[1];
}
}
return undefined;
}
remove(key) {
const index = this._hash(key);
if (!this.table[index]) return false;
for (let i = 0; i < this.table[index].length; i++) {
if (this.table[index][i][0] === key) {
this.table[index].splice(i, 1);
return true;
}
}
return false;
}
}
// Example usage
const ht = new HashTable();
ht.set('name', 'Alice');
ht.set('age', 30);
ht.set('country', 'Wonderland');
console.log(ht.get('name')); // Output: Alice
console.log(ht.get('age')); // Output: 30
ht.remove('age');
console.log(ht.get('age')); // Output: undefined
Handling Collisions
In a hash table, collisions occur when two keys hash to the same index. There are several strategies to handle collisions:
-
Chaining: Each bucket points to a linked list of entries that map to the same index. When a collision occurs, the new entry is added to the linked list.
-
Open Addressing: When a collision occurs, the hash table searches for the next available slot. There are different methods of open addressing:
- Linear Probing: If a collision occurs at index
i, the table checks the next sloti+1, theni+2, and so on, until an empty slot is found. - Quadratic Probing: Similar to linear probing, but instead of checking the next slot linearly, it checks the slots at intervals of 1, 4, 9, 16, and so on.
- Double Hashing: Uses a second hash function to determine the step size when a collision occurs.
- Linear Probing: If a collision occurs at index
we're not gonna go deep into handling collision, but be aware there is more to it.
Practical Example in Node.js with JSON-based Database (LowDB)
Let’s build a simple in-memory hash table to illustrate the concept and its benefits using LowDB.
Setup LowDB
npm install lowdb
Implement a Hash Table with LowDB
const { Low, JSONFile } = require('lowdb');
const { join } = require('path');
// Setup LowDB
const file = join(__dirname, 'db.json');
const adapter = new JSONFile(file);
const db = new Low(adapter);
class PersistentHashTable {
constructor() {
this.init();
}
async init() {
await db.read();
db.data ||= { hashTable: {} };
await db.write();
}
_hash(key) {
let hash = 0;
for (let i = 0; i < key.length; i++) {
hash = (hash << 5) - hash + key.charCodeAt(i);
hash |= 0; // Convert to 32bit integer
}
return hash % 100; // Using a fixed size for simplicity
}
async set(key, value) {
const index = this._hash(key);
await db.read();
if (!db.data.hashTable[index]) {
db.data.hashTable[index] = [];
}
db.data.hashTable[index].push([key, value]);
await db.write();
}
async get(key) {
const index = this._hash(key);
await db.read();
if (!db.data.hashTable[index]) return undefined;
for (let pair of db.data.hashTable[index]) {
if (pair[0] === key) {
return pair[1];
}
}
return undefined;
}
async remove(key) {
const index = this._hash(key);
await db.read();
if (!db.data.hashTable[index]) return false;
for (let i = 0; i < db.data.hashTable[index].length; i++) {
if (db.data.hashTable[index][i][0] === key) {
db.data.hashTable[index].splice(i, 1);
await db.write();
return true;
}
}
return false;
}
}
// Example usage
(async () => {
const pht = new PersistentHashTable();
await pht.set('name', 'Alice');
await pht.set('age', 30);
await pht.set('country', 'Wonderland');
console.log(await pht.get('name')); // Output: Alice
console.log(await pht.get('age')); // Output: 30
await pht.remove('age');
console.log(await pht.get('age')); // Output: undefined
})();
Final notes
A hash table explicitly uses a hash function to manage key-value pairs in a way that optimizes for quick lookup. Simply hashing property names in an object does not make it a hash table. A hash table involves a more complex structure and logic to handle collisions and ensure efficient data retrieval. This implementation demonstrates how hash tables can efficiently manage key-value pairs in both in-memory and persistent storage scenarios.
- #javascript
- #hashtable
- #table
- #lowdb